本文主要介绍 HDFS 性能测试工具的功能、参数说明、读写性能测试使用方法及结果分析。
简介
TestDFSIO是Hadoop系统自带的基准测试组件,用于测试Hadoop文件系统通过MapReduce方式处理作业的IO 属性。TestDFSIO调用一个MapReduce作业来并发地执行读写操作,每个map任务用于读或写每个文件,reduce 用于累积统计信息,并产生统计总结。
源码地址
hadoop/TestDFSIO.java at trunk · apache/hadoop
https://github.com/apache/hadoop/blob/trunk/hadoop-mapreduce-project/hadoop-mapreduce-client/hadoop-mapreduce-client-jobclient/src/test/java/org/apache/hadoop/fs/TestDFSIO.java
参数解析
1 | [root@manager ~]# hadoop jar /usr/hdp/3.0.1.0-187/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-tests.jar TestDFSIO |
- read:读测试,对每个文件读-size指定的字节数
- write:写测试,对每个文件写-size指定的字节数
- append:追加测试,对每个文件追加-size指定的字节数
- truncate:截断测试,对每个文件截断至-size指定的字节数
- clean:清除TestDFSIO在HDFS上生成数据
- n:文件个数
- size:每个文件的大小,必须加单位,单位可为B、KB、MB、GB、TB
- resFile:生成测试报告的本地文件路径,多次测试可使用同一个文件,结果会追加
- bufferSize:每个mapper任务读写文件所用到的缓存区大小,默认为1000000字节。
测试步骤
清理缓存
在每个DataNode节点执行
1 | sync |
这里主要是清理cache/buffer,可以通过free -h命令查看。缓存(cached)是把读取过的数据保存起来,重新读取时若命中(找到需要的数据)就不要去读硬盘了,若没有命中就读硬盘。缓冲(buffers)是根据磁盘的读写设计的,把分散的写操作集中进行,减少磁盘碎片和硬盘的反复寻道,从而提高系统性能。
sync是将cache/buffer持久化至磁盘echo 3 > /proc/sys/vm/drop_caches是清理cache/buffer区。
清除测试数据
以下命令均使用hdfs用户执行
1 | su hdfs |
写文件测试
写10个100M的文件
1 | hadoop jar /usr/hdp/3.0.1.0-187/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-tests.jar TestDFSIO -write -nrFiles 10 -size 100MB -resFile /tmp/DFSIO-write.out |
查看结果
1 | cat /tmp/DFSIO-write.out |
结果解析:
- Date & time:结果输出时间;
- Number of files:文件数量,本次执写10个文件,也是task数量,即任务数;
- Total MBytes processed:总共处理的文件大小,即数据总量,以MB为单位,因为本次写10个文件,每个文件100M,所以这里是10*100=1000;
- Throughput mb/sec:吞吐量,以MB/s为单位,计算方法是:(数据总量)/(每个map任务实际写入数据的执行时间之和);
- Average IO rate mb/sec:平均IO速率,单位MB/s,计算方法是:(每个map需要写入的数据量/每个map任务实际写入数据的执行时间)之和/任务数;
- IO rate std deviation:IO速率标准差;
- Test exec time sec:测试执行时间,单位:s。
查看数据
1 | hadoop fs -du -h /benchmarks/TestDFSIO/io_data |
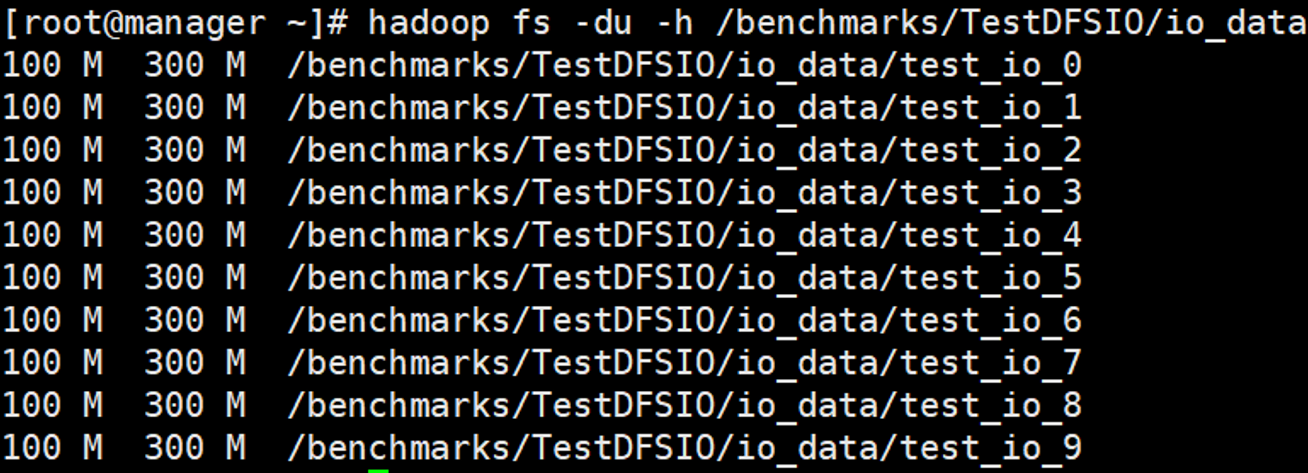
读文件测试
执行读测试时,首先需要有文件,因此可在写文件测试之后执行相应的读文件测试,这里读取10个文件,每个文件100M。
1 | hadoop jar /usr/hdp/3.0.1.0-187/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-tests.jar TestDFSIO -read -nrFiles 10 -size 100MB -resFile /tmp/DFSIO-read.out |
查看结果
1 | cat /tmp/DFSIO-read.out |
清除测试数据
1 | hadoop jar /usr/hdp/3.0.1.0-187/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-tests.jar TestDFSIO -clean |
执行脚本
为了方便测试,可使用脚本执行,如下是执行数据文件数分别为10个、100个、1000个和10000个,每个文件为128M的读写测试,且执行三遍,这样可以求取平均值,更准确。
1 | #/bin/bash |
参考资料
[Hadoop] 使用DFSIO测试集群I/O性能_mryqu_新浪博客
http://blog.sina.com.cn/s/blog_72ef7bea0102vr44.html
linux下的缓存机制buffer、cache、swap - 运维总结 - 散尽浮华 - 博客园
https://www.cnblogs.com/kevingrace/p/5991604.html
TestDFSIO基准测试方法介绍_湖南频道_凤凰网
http://hunan.ifeng.com/a/20190613/7496675_0.shtml